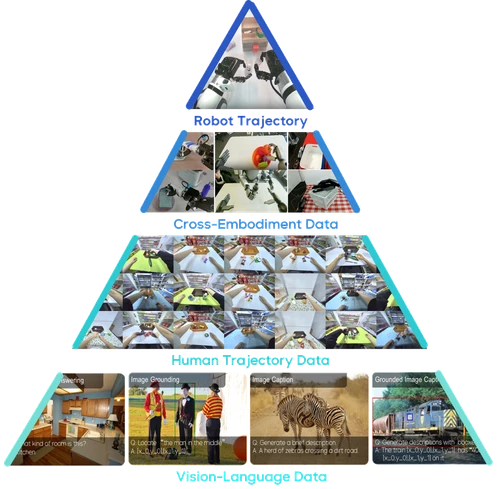
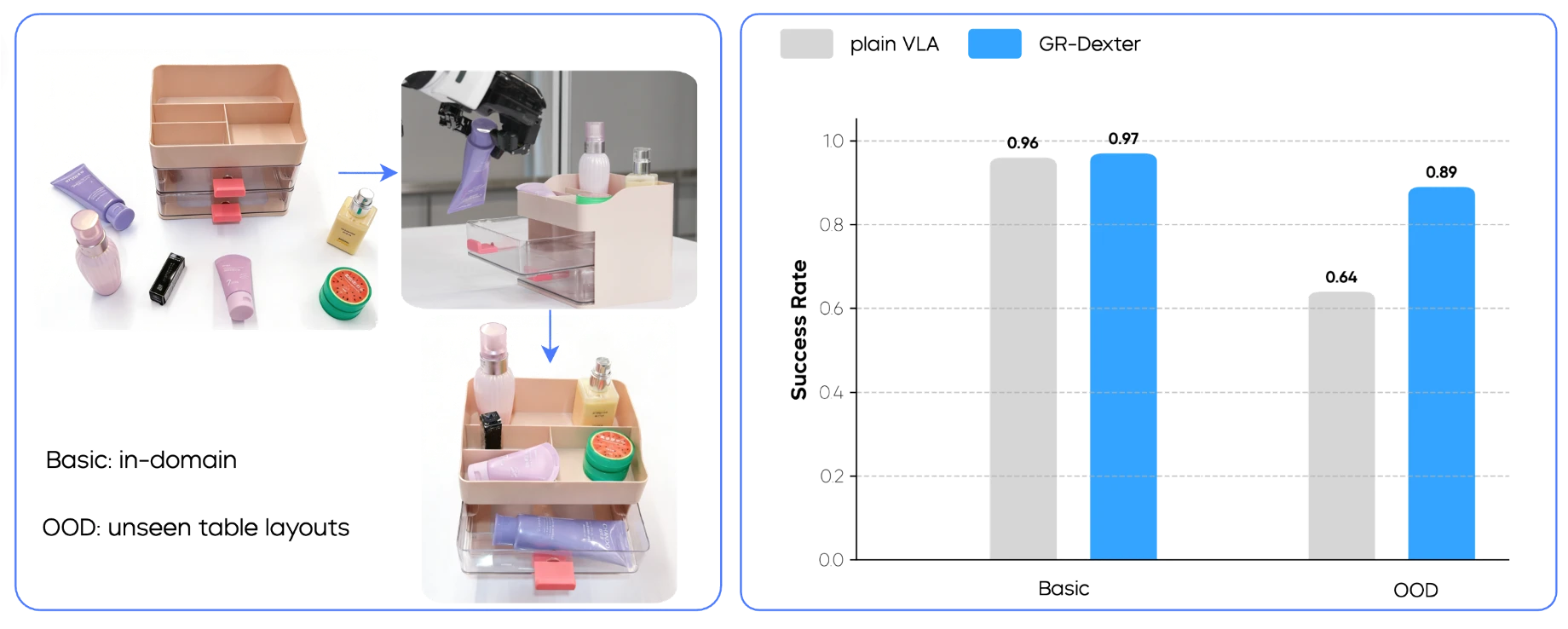
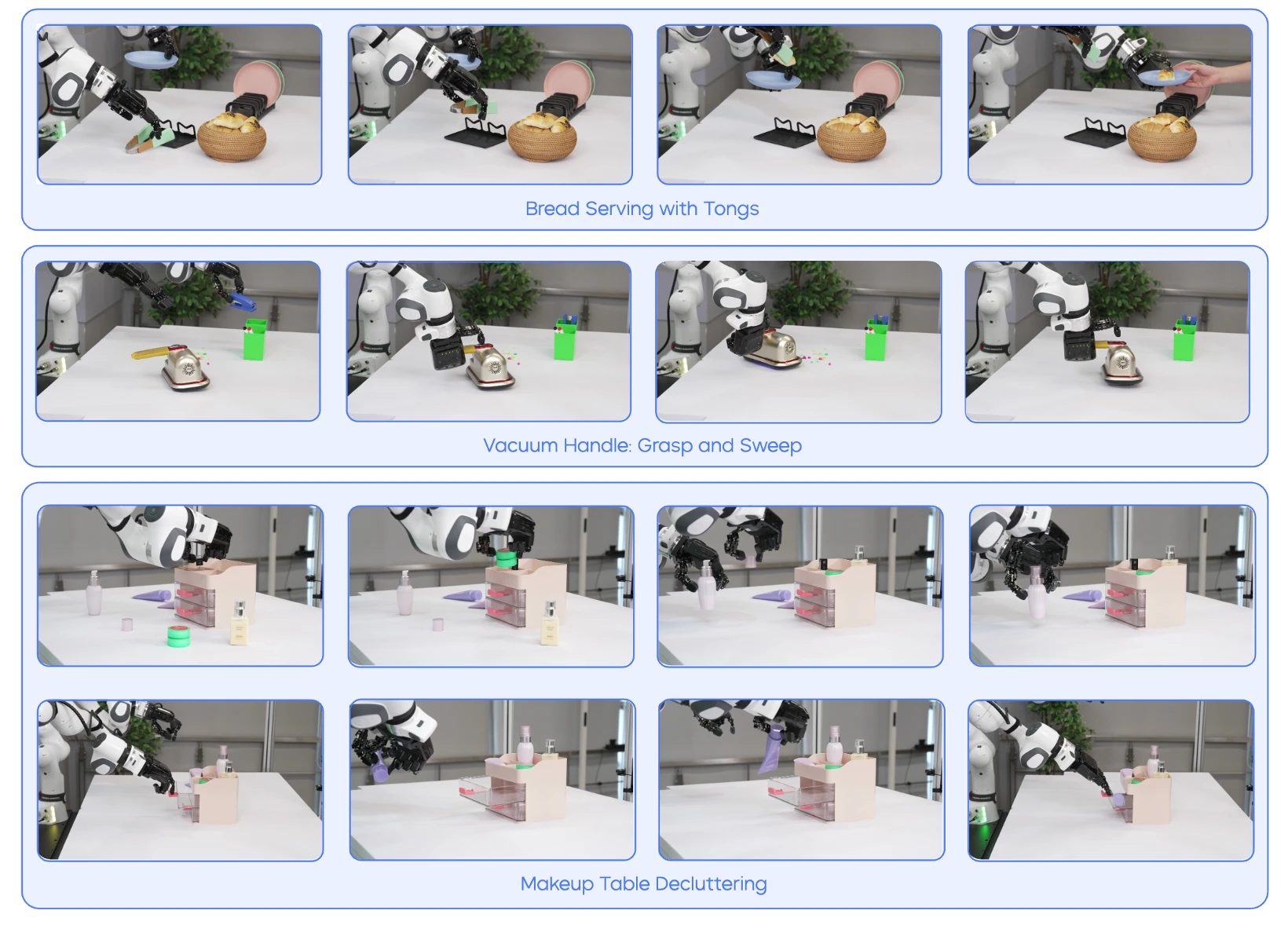
Hardware and Control
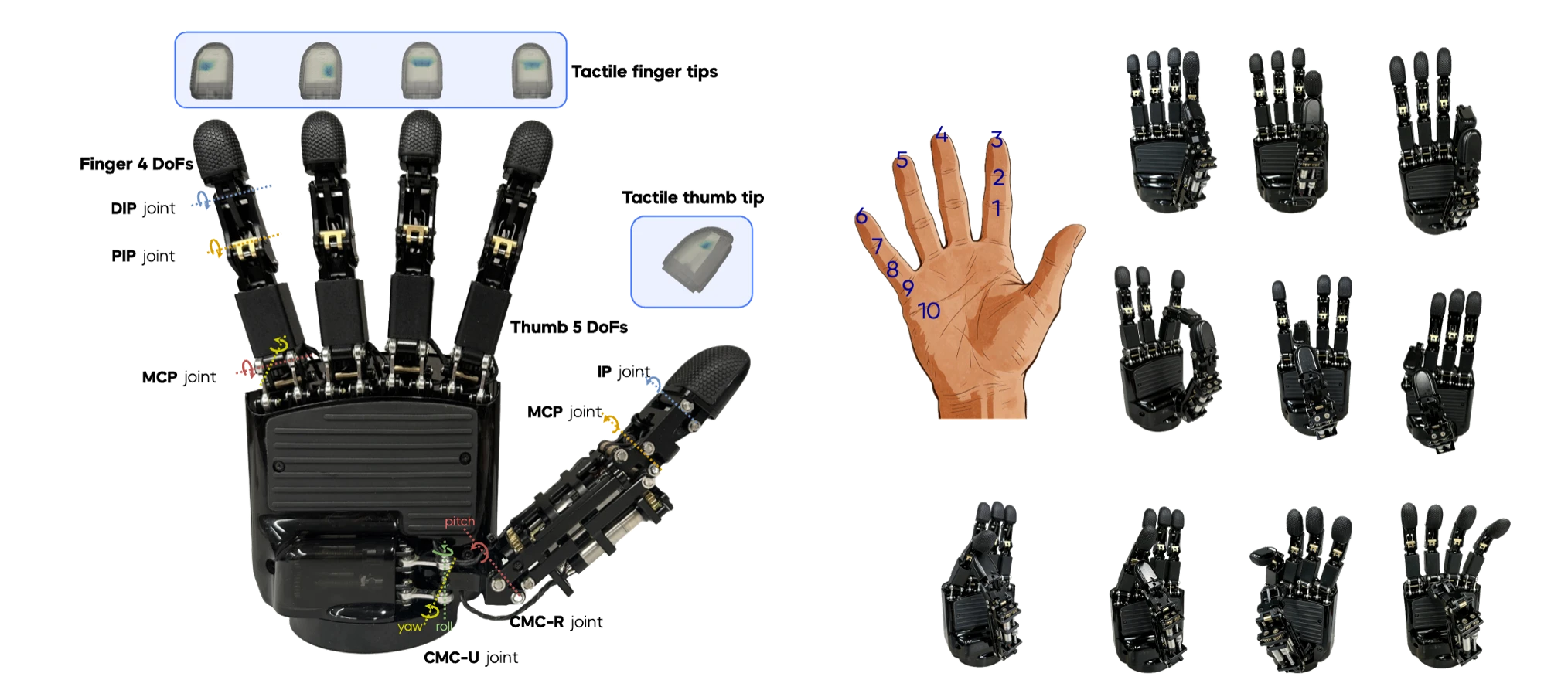
ByteDexter Robotic Hand
The ByteDexter hand series employ a linkage-driven transmission mechanism for its advantages in force transparency, durability, and ease of maintenance. As an upgraded successor to the V1 hand, the ByteDexter V2 hand introduces an additional thumb DoF, bringing the total to 21 DoFs, while simultaneously reducing the overall hand size (height: 219mm, width: 108mm). Each finger provides four DoFs, and the thumb incorporates five to enable a wider range of oppositional and dexterous motions. The five fingertips of ByteDexter V2 are covered with high-density piezoresistive sensor arrays that measures normal forces with fine spatial granularity across the finger tip, finger pad, and fingertip’s lateral surface.